|
I am a 2nd-year PhD student at Tianjin University, supervised by Prof. Changqing Zhang. My research interests include Large Reasoning Models, Out-of-Distribution Detection/Generalization and Multimodal Learning. I received my Bachelor's degree in School of Computer Science from Tianjin University. After that, I pursued my Master's in the School of Computer Science at Tianjin University and transitioned into a PhD candidate through the direct doctoral program (2+4) in 2024. During my research journey, I had wonderful time at Tencent AI Lab and Shanghai AI Lab.
Email / Google Scholar / Github / 中文简历 / |

|
|
[2025-12] Gave a talk about "LLM RL with Internal Reward" @ BUAA. [2025-09] One paper about Unsupervised LLM Reasoning Incentivization has been accepted by NeurIPS as a Spotlight. [2025-06] Starting an internship at Shanghai AI Lab, mentored by Dr. Ganqu Cui. [2025-06] Gave a talk about "LLM RL with Internal Reward" @ Huawei 2012 Lab. [2025-01] One paper about test-time adaption has been accepted by ICLR. [2024-05] One paper about Out-of-distribution Detection has been accepted by NeurIPS. [2024-05] We release a survey about fusion of low-quality multi-modal data. [arXiv] [2024-04] Starting an internship at Tencent AI Lab, mentored by Dr. Yatao Bian. [2023-04] Two paper accepted by ICML including one Oral paper, thanks to all co-authors. |
|
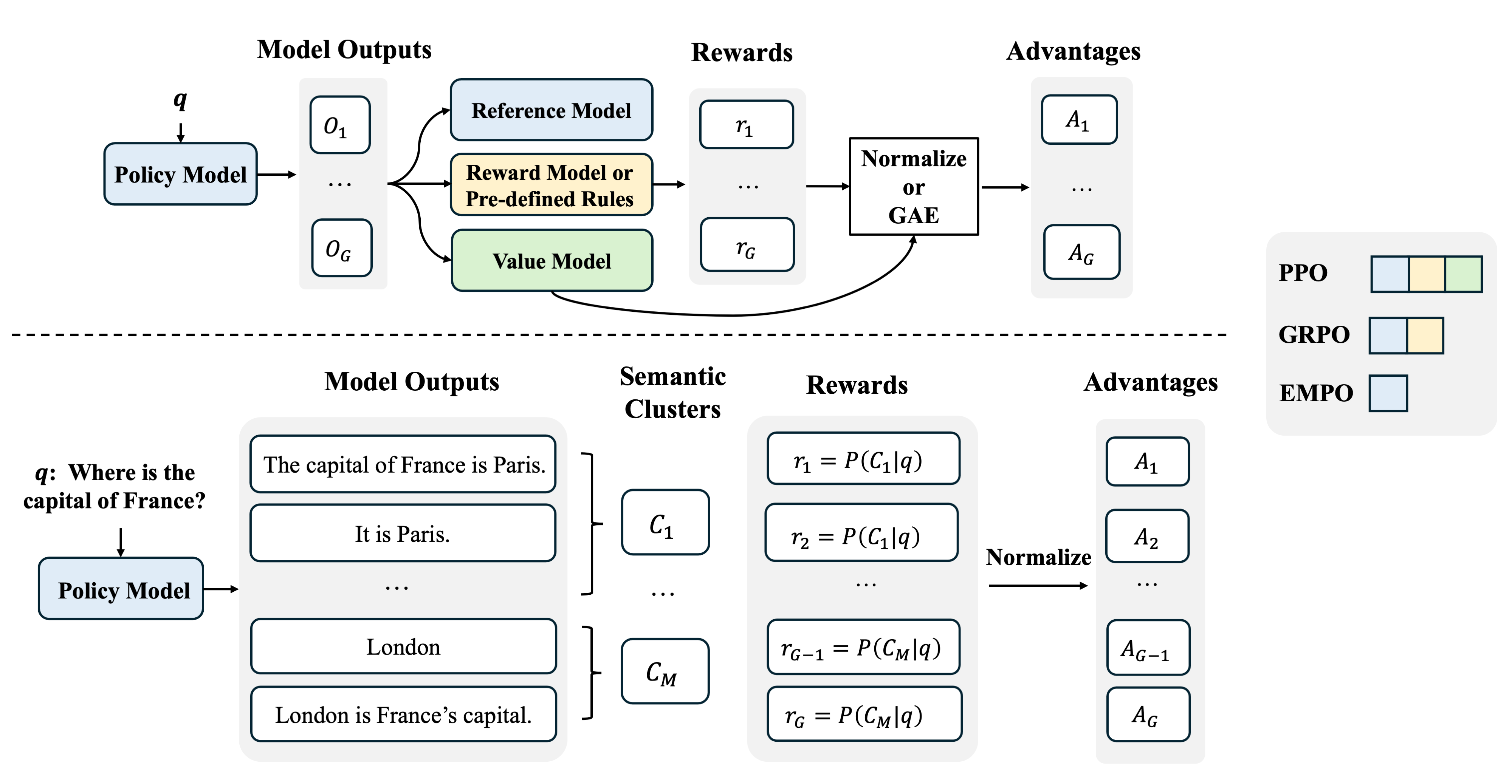
Qingyang Zhang, Haitao Wu, Changqing Zhang, Peilin Zhao, Yatao Bian NeurIPS Spotlight, 2025 arXiv / code Incentivizate LLM's reasoning capability without any external supervision (human-verified reasoning trace, golden answer or pretrained reward model). |
|
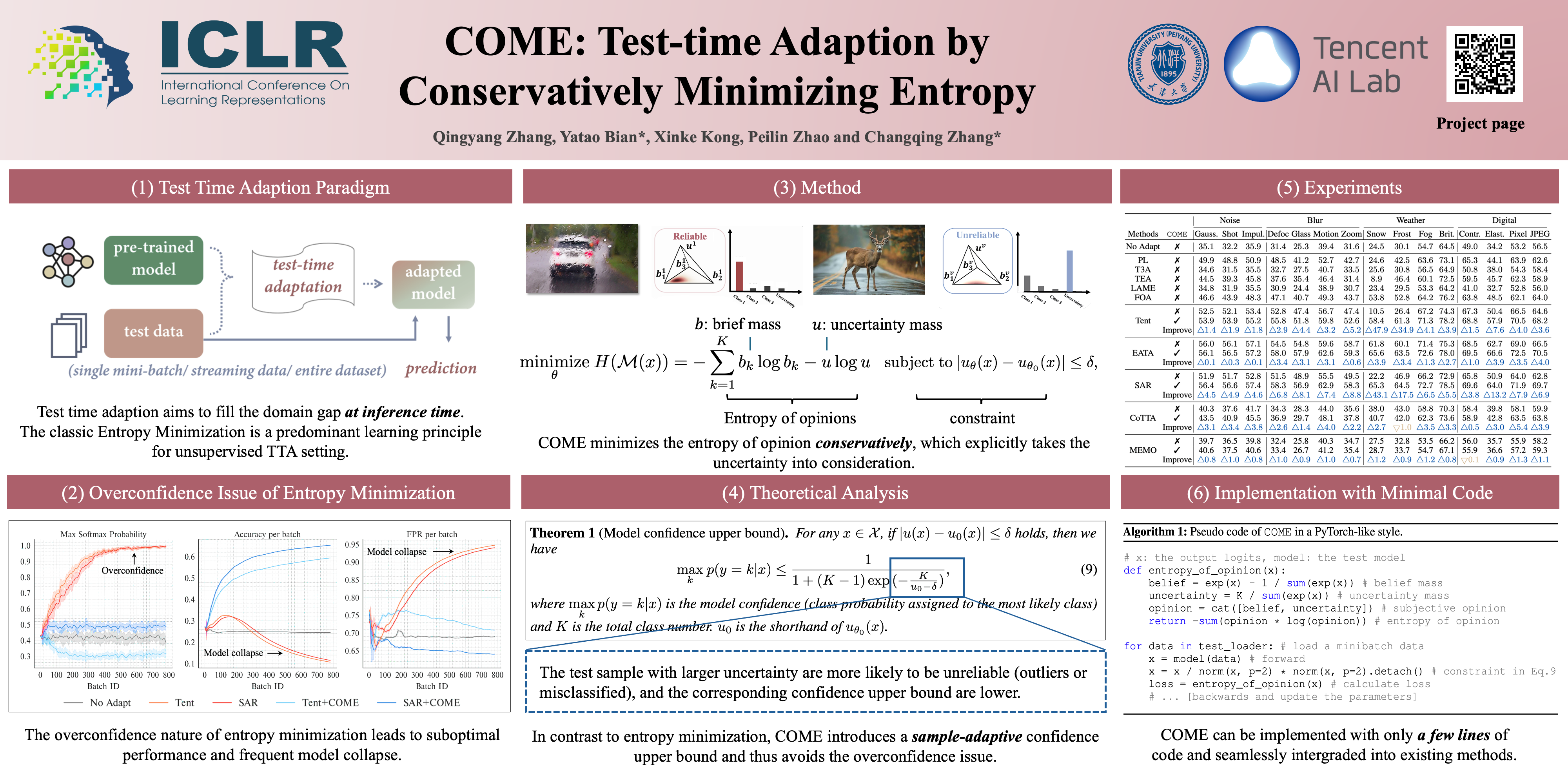
Qingyang Zhang, Yatao Bian, Xinke Kong, Peilin Zhao and Changqing Zhang ICLR, 2025 arXiv / code A simple learning principle for test time adaption. |

|
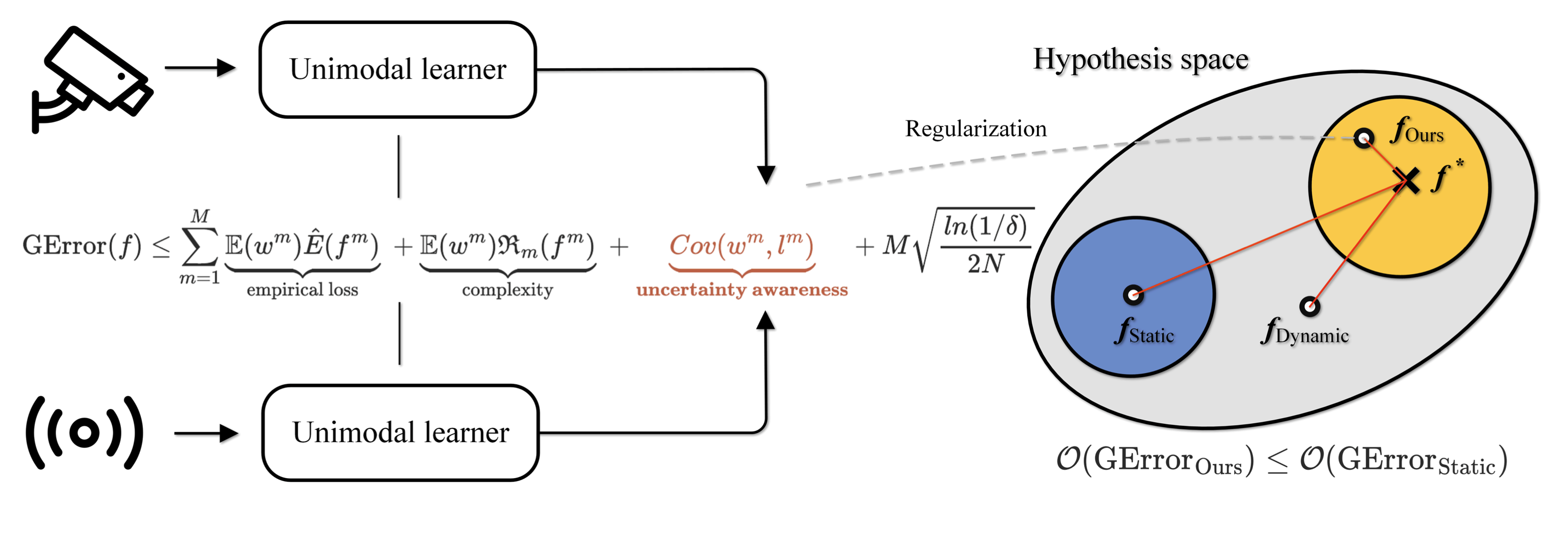
Qingyang Zhang, Qiuxuan Feng, Joey Tianyi Zhou, Yatao Bian, Qinghua Hu and Changqing Zhang NeurIPS, 2024 arXiv / code Solve conflicts between OOD detection and generalization for dual-optimal performance. |
|
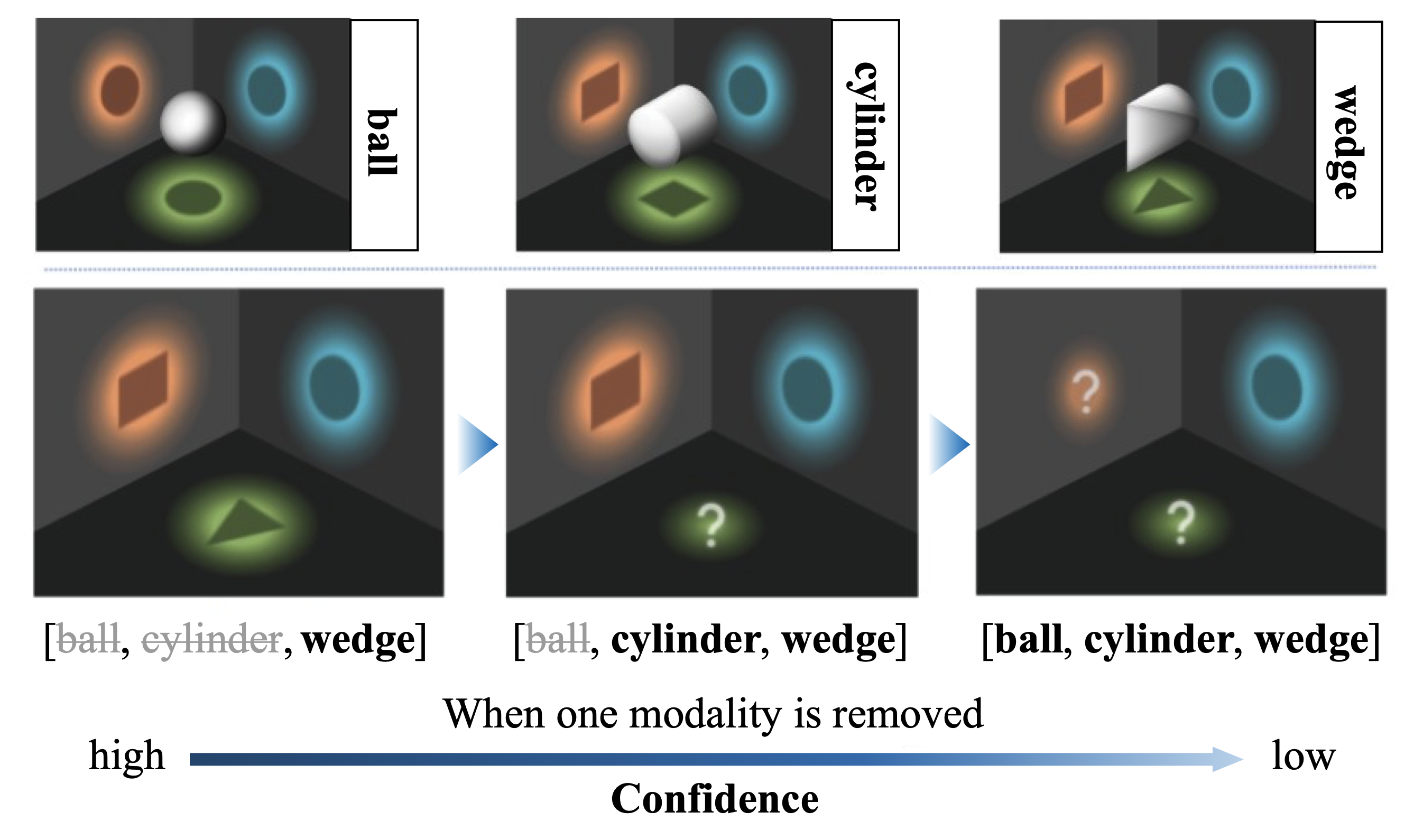
Qingyang Zhang, Haitao Wu, Changqing Zhang, Qinghua Hu, Huazhu Fu, Joey Tianyi Zhou, Xi Peng ICML, 2023 arXiv / code Theory-inspired dynimical fuse strategy for quality-varying modalities in real world. |
|
Huan Ma, Qingyang Zhang (co-first author), Changqing Zhang, Bingzhe Wu, Huazhu Fu, Joey Tianyi Zhou, Qinghua Hu ICML Oral, 2023 arXiv / code Mitigate the greedy nature of multimodal learning by regularizing the model confidence. |
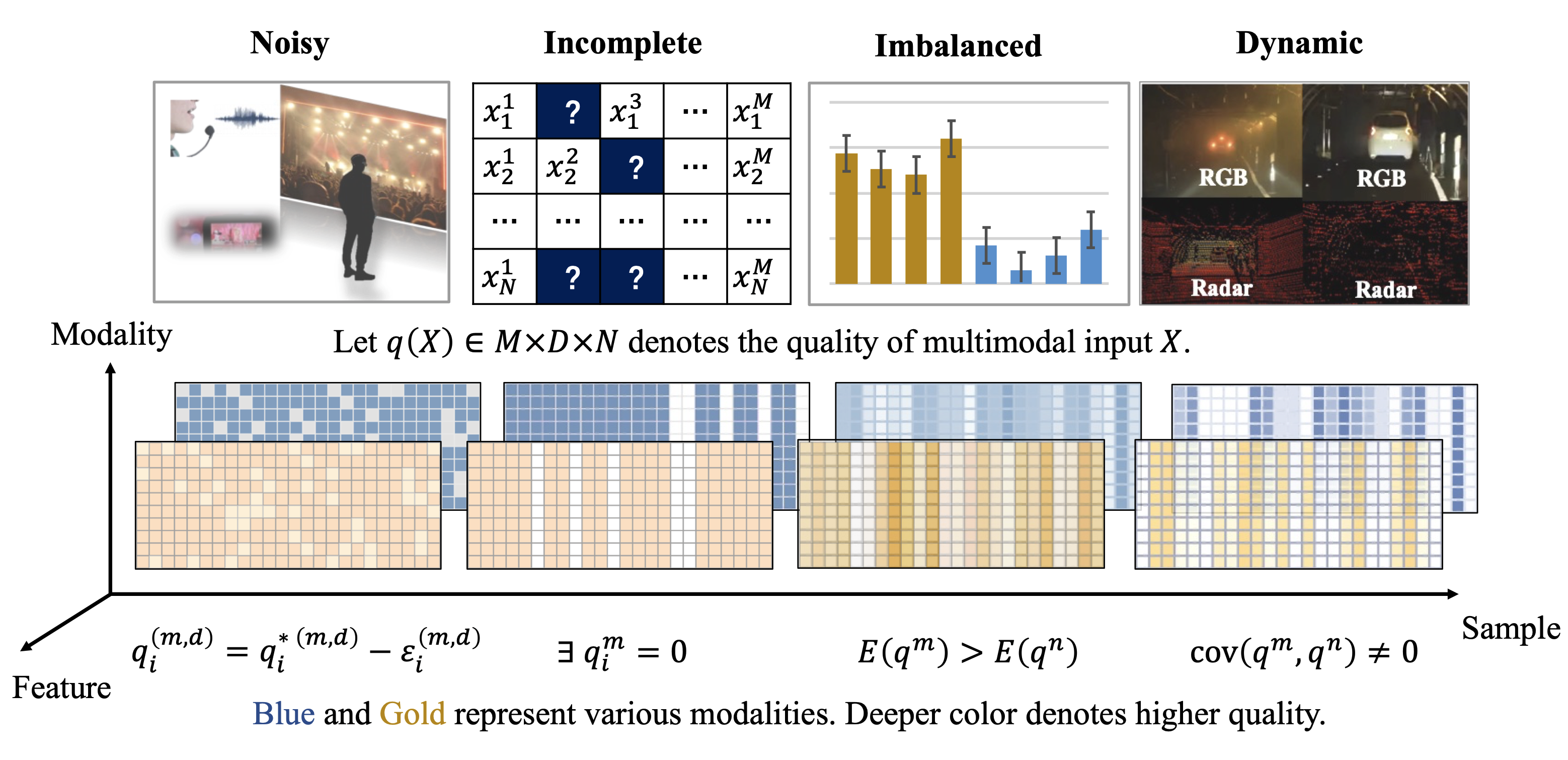
|
Qingyang Zhang, Yake Wei, Zongbo Han, Huazhu Fu, Xi Peng, Cheng Deng, Qinghua Hu, Cai Xu, Jie Wen, Di Hu, Changqing Zhang arXiv / awesome list A systematical survey about fusion of low-quality multi-modal data. |
|
Conference Reviewer: ICLR 2022-2026, NeurIPS 2023-2025, ICML 2024-2025 |
|
National Scholarship (twice, 1%) 2022, 2023 |
|
Last updated at Apr. 2025
Thanks Jon Barron for this amazing template.
|